Your AI SRE needs better observability, not bigger models.
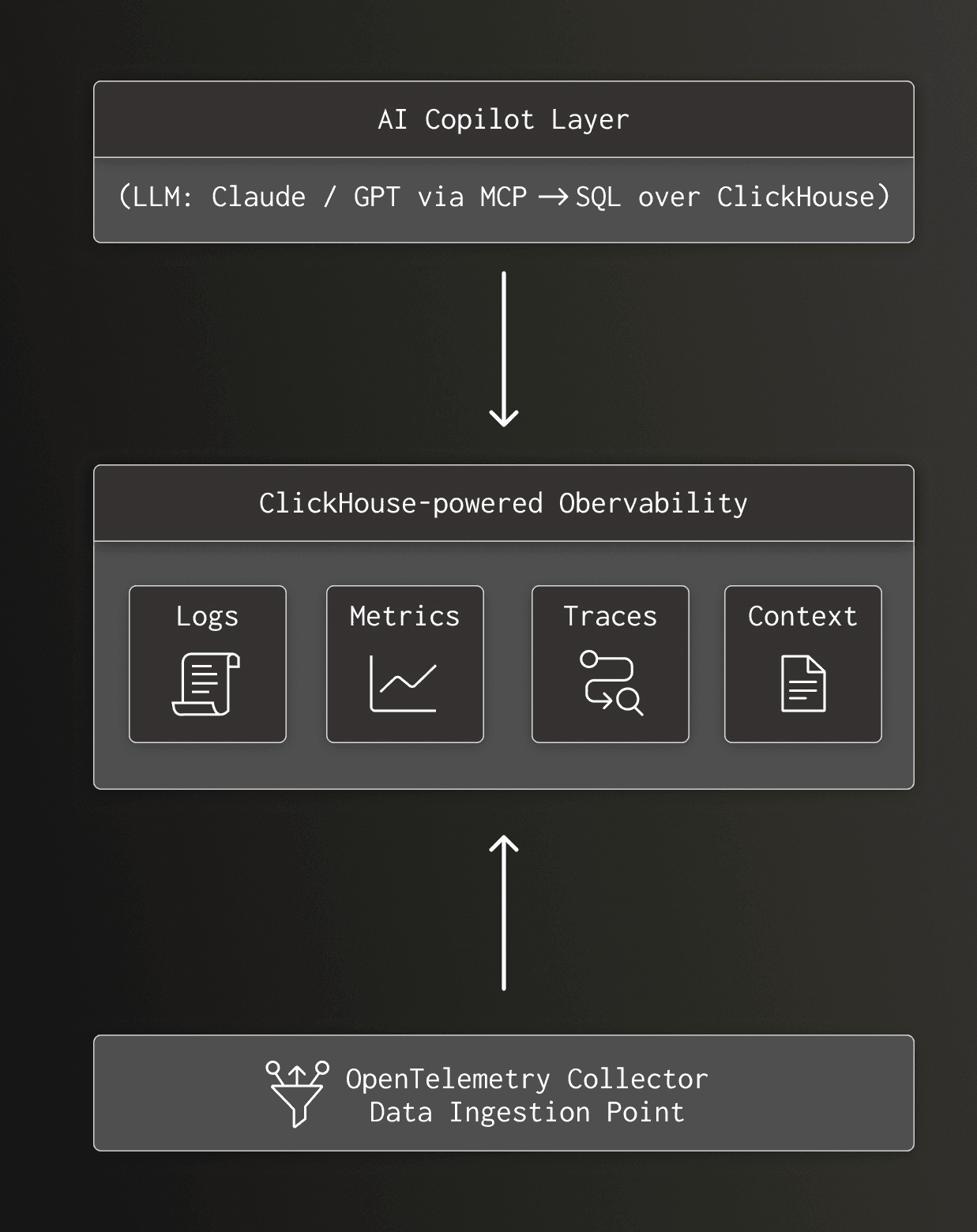
Most “AI SRE copilot” demos look great until you’re in a real incident: the model confidently narrates dashboards, but it can’t reliably isolate the true root cause. This post argues that the bottleneck isn’t LLM intelligence — it’s the observability substrate. If you only keep 7–14 days of logs, drop high-cardinality dimensions (request IDs, feature flags, regions), and split telemetry across multiple tools, the model is forced to reason over partial context.
The author frames the useful version of an AI SRE as an investigator (human-in-the-loop): the agent iterates through hypotheses by running many small queries, correlating signals, and surfacing likely causes so the on-call engineer can decide what to do. In ClickHouse’s own experiments, an investigation can take 6–27 queries; if each query is slow or expensive (or your platform bills per query), the feedback loop collapses. The suggested architecture is to centralize logs/metrics/traces plus “context tables” (deployments, feature flag changes, incident history) in a database optimized for high-cardinality, analytical SQL with long retention, so the agent can query broadly but only bring small result slices back into the prompt.