Build an Enterprise RAG Pipeline Blueprint
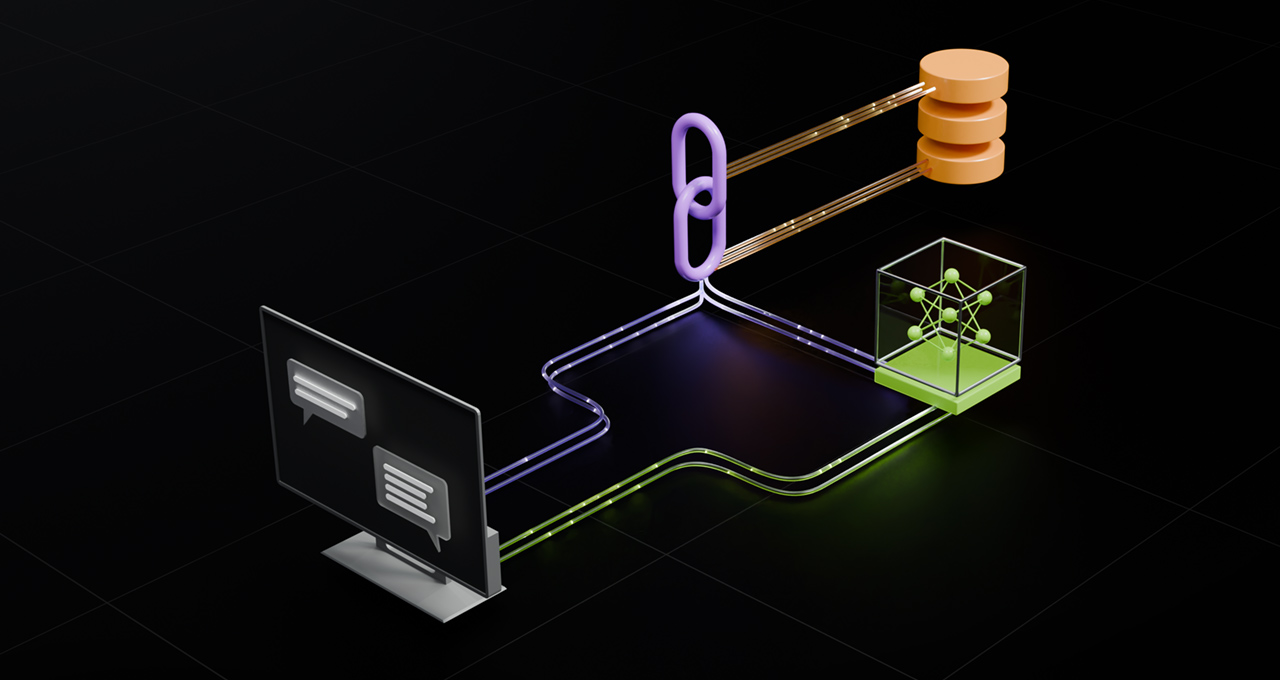
This is NVIDIA’s “batteries included” Retrieval-Augmented Generation blueprint: a reference solution for grounding LLM answers in enterprise documents using a set of GPU-accelerated microservices (NIM) plus an orchestration layer.
The GitHub repo is the interesting part. It’s decomposable (you can swap components) but comes with a working end-to-end pipeline: multimodal ingestion/extraction (including text, tables, charts, and other document structure), dense + sparse retrieval, reranking, optional query decomposition/reflection steps, and guarded answer generation. The included architecture also calls out operational concerns that many RAG demos skip: observability/telemetry, multiple deployment modes (local Docker and Kubernetes), and pluggable vector database options.
What to try first: run the default setup against a small but “messy” internal dataset (PDFs with tables/charts are ideal), then compare three knobs: hybrid vs. dense-only retrieval, reranking on/off, and max context length passed into generation. Those three toggles usually explain 80% of the quality vs. latency tradeoff you’ll feel in production.
Source listing: https://build.nvidia.com/blueprints?filters=publisher%3Anvidia